Apparently I do not have any customers that do not fill their Ceph clusters to the brim. Either because the lack capacity management, do not know their usage (patterns), or do not buy more storage nodes — for one or another reason.
This leaves me in the situation to help get the cluster in order.
Disclaimer
This is not a in depth guide for which steps to take exactly but a jumping off point to do your own reading in the Ceph documentation and acting accordingly. When in doubt, reach out to professionals, e.g. on the Mailing List or in IRC.
Obvious Things to Act on
Assuming we are not in a critical state yet, where we can no longer use the cluster. A few steps are fairly obvious but worth reiterating:
- Understand where data is coming from
- Stop the ingress of new data
- Delete unneeded data (also unneeded snapshots)
After that you can take a look at how to prevent the cluster filling up in the mid to long term, e.g. retention mechanisms, etc.
Ceph’s Balancing Mechanisms
If the cluster reports “nearfull” and “backfillfull” there is still time and you should check how well balanced your cluster is. Due to how RADOS objects are placed into Placement Groups (PG) using CRUSH PGs can differ — in some cases quite widely — in size. The PGs are being assigned to Ceph OSDs and due to chance you end up with one Ceph OSDs containing multiple large PGs and another Ceph OSD containing only small PGs. In an ideal world every PG and Ceph OSD would have the same size and the distribution would even and would grow even. But, alas, PG sizes vary (especially between pools), Ceph OSDs have different sizes and the storage usage is unevenly distributed. To fight this, Ceph has the Balancer Module that tries to do its best to optimize a low spread of different usages. Make sure it is enabled and used “upmap”.
ceph balancer status
Another variable that can be tuned automatically by Ceph is PGs per pool. It
takes in some variables like pool usage, target size and target ratio to
calculate the ideal pg_num count for the pools it is enabled on. I recommend
to at least put this on warn for every pool, if you have no reason not to.
I did have some issues in the past with it but nonetheless it is worth at
least getting some advice from it.
ceph osd pool autoscale-status
The autoscaler is a good starting point especially, if you do not know the exact distribution of your data at the beginning. In the past PG count always had to be calculated manually with a target count of approximately 100 PGs per OSD. There is PG Calc to do this manually and it is still useful today.
Ideally you know your target pool sizes or at least ratios and set the values accordingly for each pool and let the autoscaler do the rest. Or you can set the bulk flag for your data pools.
It is worth checking the PG distribution yourself with PG Calc and see if you have enough PGs per OSD. If you have only about 50 PGs per OSD increasing the PG count can help achieve better balancing and faster recovery times. The reasons for this are fairly simple: If you have more and smaller PGs the likelihood of one PG getting larger is lower and the chance of multiple large PGs ending up on one OSD is lower as well.
Looking at ceph osd df, and ceph balancer eval can give you an idea how well
your data is distributed.
Example of Increasing PG Counts
This is from a purely replicated RADOS cluster with HDDs OSDs only (except for the RocksDB).
Before:
❯ ceph balancer eval
current cluster score 0.041072 (lower is better)
❯ # awk filters relevant information: min/max OSD, total, PG/OSD, and variance
❯ ceph osd df |awk -v min=100 -v max=0 \
'/VAR/ {print}
/hdd/ { if($17<min){min_line=$0;min=$17}; if($17>max) {max_line=$0;max=$17} }
/TOTAL/ { print min_line; print max_line; print "Total:", sum, "TiB"; print "PG/OSD:", pg/c }'
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
129 hdd 9.27039 1.00000 9.3 TiB 4.2 TiB 4.0 TiB 4.6 MiB 8.8 GiB 5.1 TiB 45.30 0.73 48 up
62 hdd 9.27039 1.00000 9.3 TiB 7.4 TiB 7.2 TiB 6.3 MiB 18 GiB 1.9 TiB 79.65 1.29 64 up
Total: 1374.5 TiB
PG/OSD: 57.8458
MIN/MAX VAR: 0.73/1.29 STDDEV: 6.47
All pools have been set to ceph osd pool set <pool-name> pg_autoscale_mode warn and some of them have been assigned the bulk flag (ceph osd pool set <pool-name> bulk true) to make the autoscaler expect more data in this pool
(usually your RBD pool, RGW data pool, or CephFS data pool).
After:
❯ ceph balancer eval
current cluster score 0.025255 (lower is better)
❯ # awk filters relevant information: min/max OSD, total, PG/OSD, and variance
❯ ceph osd df |awk -v min=100 -v max=0 \
'/VAR/ {print}
/hdd/ { sum+=$7; c+=1; pg+=$19; if($17<min){min_line=$0;min=$17}; if($17>max) {max_line=$0;max=$17} }
/TOTAL/ { print min_line; print max_line; print "Total:", sum, "TiB"; print "PG/OSD:", pg/c }'
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
56 hdd 9.27039 1.00000 9.3 TiB 4.9 TiB 4.7 TiB 1.2 MiB 10 GiB 4.4 TiB 52.47 0.86 76 up
170 hdd 9.27039 1.00000 9.3 TiB 6.5 TiB 6.3 TiB 1.1 MiB 13 GiB 2.8 TiB 70.20 1.16 98 up
Total: 1351.3 TiB
PG/OSD: 86.6458
MIN/MAX VAR: 0.86/1.16 STDDEV: 3.42
After increasing pg_num for two pools and waiting for the process to finish
(took about half a week), you can see that even though the total size did
decreased a little bit (~20TiB) the variance shown by ceph balancer eval and
the standard deviation shown by ceph osd df went down. This is also reflected
by the fullest OSD being significantly lower (79% -> 70%) and the least filled
OSD being better utilised (45% -> 52%).
Note that you should also let the balancer do its job after increasing the PG count; so this could even improve a little bit.
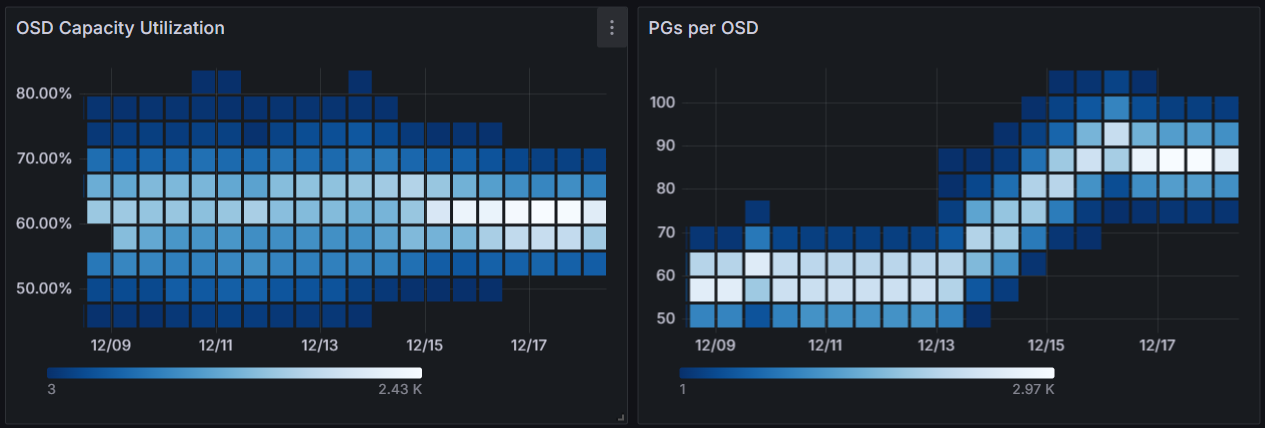
You can see with more PGs the spread of OSD capacities narrows and focuses more on a lower number which is exactly what you want to see. Interestingly, if you look at the PGs per OSD you can also see that after the initial increase in the count of PGs the distribution of PGs decreases its spread as well. This is due to the balancer now getting the chance after the data splits to optimize their placements.
Slight warning: Do not be alarmed if you get warning about (deep-)scrubs not being done on time. Since increasing PG count leads to lots of backfilling potentially over a prolonged period, Ceph prioritizes backfilling over scrubs. After the cluster is back to a static number of PGs and finished all backfilling task the number of scrubs not done on time should decrease (I would expect it to take about as long as the PG increase or less).
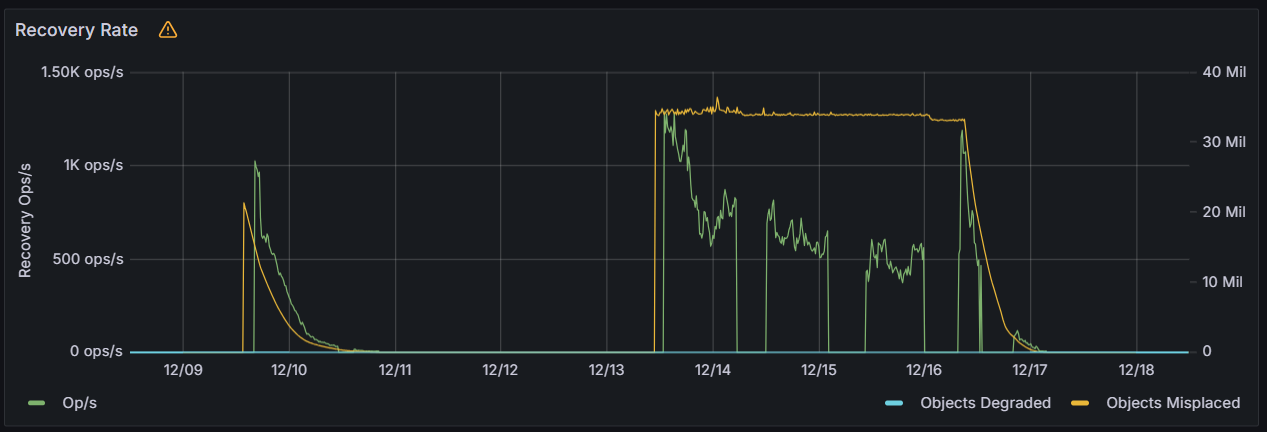
To improve recovery speed I set ceph config set osd osd_mclock_profile high_recovery_ops. To not impact daily usage too much, I set up an ad-hoc
systemd-timers:
systemd-run --on-calendar 'Mon..Fri 2024-12-* 18:00' \
ceph config set osd osd_mclock_profile high_recovery_ops
systemd-run --on-calendar 'Mon..Fri 2024-12-* 08:00' \
ceph config set osd osd_mclock_profile high_client_ops
systemd-run --on-calendar '2025-01-01 08:00' \
ceph config set osd osd_mclock_profile high_client_ops
Note: Keep in mind, that if the server these commands were run on restarts, the
timers are gone. So make sure to check that you have indeed set the proper
osd_mclock_profile after you are done. You could also remove the setting to go
back to the balance default with ceph config rm osd osd_mclock_profile
Getting Your Hands Dirty
If this is still not enough there is more you can do, by adjusting the Ceph OSD (re)weights.
The existing scripts only looked at the current utilization and acted upon this information. Then you had to wait for the result and tweak another value. I wrote a few scripts for looking at changes during backfilling and adjusting based on future balance results.
I created a repo, if you want to check them out.
Emergency Only
If you are really in a pickle and need to get a blocked cluster running again to be able to rebalance (not to use it!), you can change what is recognized as a backfillfull or full Ceph OSD. I do not recommend this!
ceph osd dump | grep ratio
ceph osd set-backfillfull-ratio $higher
ceph osd set-full-ratio $more_higher
Also, make sure to change it back after your incident!
ceph osd set-backfillfull-ratio .9
ceph osd set-full-ratio .95
ceph osd dump | grep ratio