I recently revived my Synology D415+ NAS from silicon death and it looks like it works fine again. When I bought it, I wanted to be able to run any docker image. Which is why I opted for Atom instead of ARM. Which is also why I upgraded RAM to 8GB. The disks basically never spun down which made it quite noisy. Now, I just want it to be silent, if not in use.
I initially thought I could replace the DiskStation Manager (DSM) with a proper Linux but from what I gathered, it is “not doable without deeper knowledge”.
Adjusting Fans
I only inserted the first SSD so far and installed DSM 7.0 on it. The only audible sound was the fans spinning and I found a guide to use a custom fan profile to turn them off completely for low loads.
Step one: Set “Fan Speed Mode” to “Quiet mode” via the GUI in “Hardware & Power”. This can also be done by setting
Step two: Turning off fan check to allow for 0 speed operations.
# cat /usr/local/etc/rc.d/fan_check_disable.sh <<EOF
#!/bin/sh
echo 0 > /sys/module/avoton_synobios/parameters/check_fan
EOF
# chmod 755 /usr/local/etc/rc.d/fan_check_disable.sh
Step three: Backup /usr/syno/etc.defaults/scemd.xml and usr/syno/etc/scemd.xml
Step four: Adjust fan profile as described in the guide with some modifications
in /usr/syno/etc.defaults/scemd.xml and usr/syno/etc/scemd.xml.
--- /usr/syno/etc/scemd.xml_2022-04-23 2021-10-18 15:26:05.000000000 +0200
+++ /usr/syno/etc/scemd.xml 2022-04-23 01:12:07.740595553 +0200
@@ -14,17 +14,21 @@
<cpu_temperature fan_speed="99%40hz" action="SHUTDOWN">95</cpu_temperature>
</fan_config>
<fan_config period="20" threshold="6" type="DUAL_MODE_LOW" hibernation_speed="UNKNOWN">
- <disk_temperature fan_speed="21%40hz" action="NONE">0</disk_temperature>
- <disk_temperature fan_speed="35%40hz" action="NONE">42</disk_temperature>
- <disk_temperature fan_speed="50%40hz" action="NONE">46</disk_temperature>
- <disk_temperature fan_speed="70%40hz" action="NONE">53</disk_temperature>
+ <disk_temperature fan_speed="01%40hz" action="NONE">0</disk_temperature>
+ <disk_temperature fan_speed="10%40hz" action="NONE">41</disk_temperature>
+ <disk_temperature fan_speed="20%40hz" action="NONE">46</disk_temperature>
+ <disk_temperature fan_speed="35%40hz" action="NONE">48</disk_temperature>
+ <disk_temperature fan_speed="50%40hz" action="NONE">50</disk_temperature>
+ <disk_temperature fan_speed="70%40hz" action="NONE">54</disk_temperature>
<disk_temperature fan_speed="99%40hz" action="NONE">58</disk_temperature>
<disk_temperature fan_speed="99%40hz" action="SHUTDOWN">61</disk_temperature>
- <cpu_temperature fan_speed="21%40hz" action="NONE">0</cpu_temperature>
- <cpu_temperature fan_speed="50%40hz" action="NONE">50</cpu_temperature>
- <cpu_temperature fan_speed="99%40hz" action="NONE">85</cpu_temperature>
- <cpu_temperature fan_speed="99%40hz" action="SHUTDOWN">95</cpu_temperature>
+ <cpu_temperature fan_speed="01%40hz" action="NONE">0</cpu_temperature>
+ <cpu_temperature fan_speed="10%40hz" action="NONE">57</cpu_temperature>
+ <cpu_temperature fan_speed="20%40hz" action="NONE">62</cpu_temperature>
+ <cpu_temperature fan_speed="50%40hz" action="NONE">65</cpu_temperature>
+ <cpu_temperature fan_speed="99%40hz" action="NONE">80</cpu_temperature>
+ <cpu_temperature fan_speed="99%40hz" action="SHUTDOWN">90</cpu_temperature>
</fan_config>
<fan_config hw_version="Synology-DX5" period="20" threshold="6" type="DUAL_MODE_HIGH_EBOX" hibernation_speed="FULL">
Step five: Reboot NAS
Adding Disks
If you checked out the source for the fan profile, you might have noticed that I skipped something more obvious. The IronWolf drives I bought are really loud when spun up – louder than the stock fan configuration in fact. For quiet operation they need to spin down when idle.
Looking at the md configuration I noticed something odd.
# cat /proc/mdstat
Personalities : [raid1]
md2 : active raid1 sda3[0]
239376512 blocks super 1.2 [1/1] [U]
md1 : active raid1 sda2[0]
2097088 blocks [4/1] [U___]
md0 : active raid1 sda1[0]
2490176 blocks [4/1] [U___]
unused devices: <none>
The first SSD (sda) I inserted was split into 3 partitions and turned into 3
arrays. md2 was the main bulk and what will is volume1. It is not mounted
directly to /volume1 tough, but through /dev/mapper/cachedev_0. I assume
this is to enable adding a caching device later (which makes no sense in this
case) to be more flexible.
# df -h /volume1/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/cachedev_0 220G 92G 101G 48% /volume1
# ls -l /dev/mapper/cachedev_0 /dev/md2
brw------- 1 root root 253, 0 Apr 23 11:58 /dev/mapper/cachedev_0
brw------- 1 root root 9, 2 Apr 23 11:58 /dev/md2
# dmsetup ls --tree # ^^^^^^ notice major and minor device numbers match up
cachedev_0 (253:0)
└─ (9:2)
md0(sda1) is used for / while I could not exactly figure out what
md1(sda2) was used for – I read it was swap somewhere but I could not verify
that, so don’t quote me on that.
# df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/md0 2.3G 1.2G 1.1G 52% /
Notice [U___] on both md0 and md1 and what happens after I insert a second
SSD and configure it as Storage Pool 2 (no volume) via the GUI.
# cat /proc/mdstat
Personalities : [raid1]
md3 : active raid1 sdb3[0]
120212800 blocks super 1.2 [1/1] [U]
md2 : active raid1 sda3[0]
239376512 blocks super 1.2 [1/1] [U]
md1 : active raid1 sdb2[4] sda2[0]
2097088 blocks [4/1] [U___]
[=======>.............] recovery = 37.0% (776576/2097088) finish=0.5min speed=36979K/sec
md0 : active raid1 sdb1[4] sda1[0]
2490176 blocks [4/1] [U___]
[=====>...............] recovery = 28.7% (716928/2490176) finish=0.9min speed=32587K/sec
unused devices: <none>
# cat /proc/mdstat
Personalities : [raid1]
md3 : active raid1 sdb3[0]
120212800 blocks super 1.2 [1/1] [U]
md2 : active raid1 sda3[0]
239376512 blocks super 1.2 [1/1] [U]
md1 : active raid1 sdb2[1] sda2[0]
2097088 blocks [4/2] [UU__]
md0 : active raid1 sdb1[1] sda1[0]
2490176 blocks [4/2] [UU__]
unused devices: <none>
Initializing the new disk resulted in it being split into three partitions as
well. It added the first two partitions to the RAID1 arrays md0 and md1 and
left the third partition for usage. This is kind of clever. After the initial
array sync – took a few seconds –, I could now remove the first SSD, if I wanted
without losing my operating system. I would still lose everything I installed on
the volume from this disk though. Indeed, this happens to every disk I insert and
initialize a storage pool on.
I inserted my 2 10T HDDs now, and indeed they undergo the same procedure. The
array sync took about 1-2 minutes this time and I ended up with md4 and 2 more
members for md0 and md1.
# cat /proc/mdstat
Personalities : [raid1]
md4 : active raid1 sdd3[1] sdc3[0]
9761614848 blocks super 1.2 [2/2] [UU]
[...]
md1 : active raid1 sdd2[3] sdc2[2] sdb2[1] sda2[0]
2097088 blocks [4/4] [UUUU]
md0 : active raid1 sdd1[3] sdc1[2] sdb1[1] sda1[0]
2490176 blocks [4/4] [UUUU]
[...]
This is great for simplicity and redundancy. I can yank any 3 disks and my system keeps running. But what if anything is read or written to the system disk? I expect this to hinder hibernation and spin down quite a bit.
Debugging HDD Hibernation Part 1
I found the tool /usr/syno/sbin/syno_hibernation_debug to analyse hibernation
fails (1 for “Cannot Enter Hibernation” or 2 for “Which Interrupt
Hibernation”). The older one used in many forum posts was and no longer
available (syno_hibernate_debug_tool --enable 1)
I enabled the debug log by setting some options in /etc/synoinfo.conf
enable_hibernation_debug="yes"
hibernation_debug_level="1"
I tailed /var/log/hibernationFull.log to get a feel what happens. I stopped
the tail after I realised that reading a file from the disk I want to see idle
might not work very well.
After about 600 seconds the disks spun down only to spin up again 30 seconds later. I looked at the hibernation log to see what had happened.
[Sat Apr 23 15:42:15 2022] ppid:1(systemd), pid:22779(syno_hibernatio), dirtied inode 20738 (hibernation.log) on md0
[Sat Apr 23 15:42:15 2022] ppid:1(systemd), pid:22779(syno_hibernatio), dirtied inode 20738 (hibernation.log) on md0
[Sat Apr 23 15:42:15 2022] ppid:1(systemd), pid:22779(syno_hibernatio), dirtied inode 20738 (hibernation.log) on md0
[Sat Apr 23 15:42:15 2022] ppid:1(systemd), pid:22779(syno_hibernatio), dirtied inode 30536 (hibernationFull.log) on md0
[Sat Apr 23 15:42:15 2022] ppid:1(systemd), pid:22779(syno_hibernatio), dirtied inode 30536 (hibernationFull.log) on md0
[Sat Apr 23 15:42:15 2022] ppid:1(systemd), pid:22779(syno_hibernatio), dirtied inode 30536 (hibernationFull.log) on md0
Huh, that’s the pid for the /usr/syno/sbin/syno_hibernation_debug process. Did it wake itself up?
I looked deeper into to syno_hibernation_debug script to find out what was
going on. The script mainly took care of a few things:
- Reading configuration and running itself in the background if
enable_hibernation_debug="yes"was found andhibernation_debug_levelwas1or2.- If not, it killed the running debug process
echo 1 > /proc/sys/vm/block_dumpif enabled andecho 0 > /proc/sys/vm/block_dumpif not- it loops over
/sys/block/sd{a..d}/device/syno_idle_time(in my case) to see if the idle time was below the configured standby time - then it looks at
dmesg | tail -500 - it also writes to two log files (this should be find, it calls
syncinstantly afterwards and sleeps for 20s)
This is when I gave up on the script. There really is nothing too special about it that I cannot do by hand without waking the disks up by myself. But I still have the feeling that internals might be at play that will always sync the array at some point in time. I don’t want the system to be on HDDs.
I tried again, this time by hand.
echo 1 > /proc/sys/vm/block_dump
while sleep 1s; do cat /sys/block/sd{a..d}/device/syno_idle_time; echo; done
This time is was something else.
[Sat Apr 23 16:41:17 2022] ppid:1(systemd), pid:14381(scemd), dirtied inode 30475 (disk_overview.xml) on md0
[Sat Apr 23 16:41:17 2022] ppid:1(systemd), pid:14381(scemd), dirtied inode 30475 (disk_overview.xml) on md0
I wonder, if I missed this the first time, but dmesg does not go back far
enough and I am not willing to spend the time again. The other reason is that I
will definitely do something about the HDDs in the array. Simply ssh-ing to the
NAS wakes it up – reading authorized_keys or something? Probably more,
logging, etc.?
Removing HDDs from Array
The fact that the idle times if all four disks (2xSSD, 2xHDD) were almost always in sync to the same value, makes me sure that with this configuration it will be very hard to achieve total silence with spin down or even debug it properly.
I removed the HDD partitions form arrays md0 and md1.
mdadm /dev/md0 --fail /dev/sdc1
mdadm /dev/md0 --remove /dev/sdc1
mdadm /dev/md0 --fail /dev/sdd1
mdadm /dev/md0 --remove /dev/sdd1
mdadm /dev/md1 --fail /dev/sdc2
mdadm /dev/md1 --remove /dev/sdc2
mdadm /dev/md1 --fail /dev/sdd2
mdadm /dev/md1 --remove /dev/sdd2
Resulting in this (notice that I ):
# cat /proc/mdstat
Personalities : [raid1]
md4 : active raid1 sdd3[1] sdc3[0]
9761614848 blocks super 1.2 [2/2] [UU]
[...]
md1 : active raid1 sdb2[1] sda2[0]
2097088 blocks [4/2] [UU__]
md0 : active raid1 sdb1[1] sda1[0]
2490176 blocks [4/2] [UU__]
[...]
Synology did not like that.
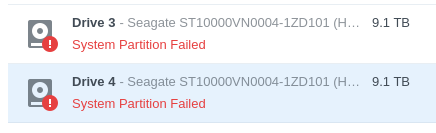 Important: Do not shrink the arrays. I did so at first (
Important: Do not shrink the arrays. I did so at first (mdadm /dev/md0 --grow -n 2, same for md1) but when I later rebooted the machine, it went to
the setup wizard instead. Fixing this was easy: I shut down the NAS, removed the
HDDs and booted again. After it was done, I inserted the HDDs again, and
assembled the array again (can be done via GUI).
Advice: Do not do this – unless you are sure of the consequences it might have. I expect this to break with OS upgrades and the like. Same for fan profiles.
I looked at idle times again and was pleased to see that ssh-ing to the machine only reset idle times for the remaining SSDs in the system arrays.
Sadly that did not last long since the idle time rose above 10 minutes without the disks spinning down. Did Synology stop tracking the disk for some reason?
Time to postpone for this day.
Debugging HDD Hibernation Part 2
I noticed when the HDD did spin down, looking at
/sys/block/sd{a..d}/device/syno_idle_time took longer. So this does not count
as something to interrupt the idle time but it does wake up the disk. The
syno_hibernation_debug script basically only works for checking why a disk
does not enter hibernation but not for what wakes it up, because it will wake the
disk up itself. All debugging efforts basically lead to spin-up – the German
wiki page on hibernation even touches on something like this briefly.
New approach: I disabled all debugging measures (including hibernation log),
closed all ssh connections, closed the webinterface and check for open
connections to the machine (lsof -i@$hostname_of_NAS). Time for some series, a
10-15 minute timer and listening if the disks spin down at some point. I left
echo 1 > /proc/sys/vm/block_dump to check for what woke up the drives if they
did.
With Advanced Sleep
After waiting about ten minutes the disks spun down and the yellow LEDs went off (Status and disks) while the blue power LED stayed solid. The fans did not spin up. (There was some network activity I saw on my router at a later date, mainly ARP and NTP).
When I connected to the web GUI after over an hour the disks spun up and the LED
went back on. Looking at dmesg and searching for the HDDs I saw some activity
I assume to be a result of waking up from deep sleep and checking if anything
changed with the disks.
[Sun Apr 24 17:15:56 2022] sd 5:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
[Sun Apr 24 17:16:01 2022] sd 4:0:0:0: [sdc] Write cache: disabled, read cache: enabled, doesn't support DPO or FUA
[Sun Apr 24 17:16:02 2022] sd 5:0:0:0: [sdd] Write cache: disabled, read cache: enabled, doesn't support DPO or FUA
[Sun Apr 24 17:16:26 2022] ppid:2(kthreadd), pid:30085(kworker/3:0), READ block 8 on sdd3 (8 sectors)
[Sun Apr 24 17:16:26 2022] ppid:2(kthreadd), pid:30085(kworker/3:0), READ block 8 on sdc3 (8 sectors)
[Sun Apr 24 17:16:26 2022] ppid:2(kthreadd), pid:6707(md4_raid1), WRITE block 8 on sdd3 (1 sectors)
[Sun Apr 24 17:16:26 2022] ppid:2(kthreadd), pid:6707(md4_raid1), WRITE block 8 on sdc3 (1 sectors)
[Sun Apr 24 17:16:26 2022] ppid:2(kthreadd), pid:6707(md4_raid1), WRITE block 8 on sdd3 (1 sectors)
[Sun Apr 24 17:16:26 2022] ppid:2(kthreadd), pid:6707(md4_raid1), WRITE block 8 on sdc3 (1 sectors)
I waited until the disk were silent again and the LEDs went off and connected via ssh – again, disk spin.
[Sun Apr 24 17:29:55 2022] sd 4:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
Without Advanced Sleep
My hope was, by not going into deep sleep to not wake the HDDs from their spin-down when connecting to the GUI or via ssh. After waiting 10 minutes the disks spun down but all LEDs stayed on. About every 10 minutes the fans spun up for 2-3 minutes but the disks stayed spun down. My guess would be that not going into deeps sleep the CPU and maybe the SSDs needed more power wich lead to higher temperature and thus a higher cooling need.
When I connected via ssh the HDDs spun up. There was nothing for the disks in
dmesg what had accessed the disks.
I waited for the disks to go silent again and tried the same with connecting via the GUI. Unfortunately, the disks ramped up again.
[Sun Apr 24 18:42:59 2022] ppid:2(kthreadd), pid:30021(kworker/2:1), READ block 8 on sdb3 (8 sectors)
[Sun Apr 24 18:42:59 2022] ppid:2(kthreadd), pid:30021(kworker/2:1), READ block 8 on sda3 (8 sectors)
Hunting Ghosts
This is where I put down my pen for now and talk about what I have learned on this adventure.
I guess my initial assumption that the disks didn’t properly spin down was false. Maybe I had installed something that kept disks awake back then or didn’t properly configure hibernate. Either way, do not assume something is (still) broken; verify before you invest time in debugging. For the mathematically inclined, for a complete induction it is essential to prove the base case before doing the induction step.
Measuring has its costs or there ain’t no such thing as a free lunch. When looking at metrics, surveying the data will change the data from what it would have been – reminds me of the uncertainty principle, somehow.
What’s next
I will keep my weird RAID configuration (for now), in case it did help. I am comfortable with dealing with potential fails that might occur. I moved the HDDs to the slots away from the mainboard to reduce heat radiating to them. I will keep the advanced/deep sleep configuration since there was no observable benefit from disabling deep sleep, if ssh-ing would wake up the HDDs anyways. I still do not understand this behavior and if anybody has an idea and how to fix it, please let me know.
PS: I am aware that constantly spinning disks might not wear out as fast but this is a risk I am willing to take right now.